Dynatrace Metrics Ingest
Today we’re going to be talking about some exciting new functionality that was recently added to Dynatrace. We’ve talked about Dynatrace in this blog before, but for those who may not be familiar, Dynatrace is an all-in-one software intelligence platform and a leader in the Gartner magic quadrant for APM. Dynatrace has always been a frontrunner in understanding application performance and their AI and automation help tackle many challenges that would require countless hours of manpower.
Most of the data captured in Dynatrace, up until this point, was gathered from the Dynatrace OneAgent or from Dynatrace Extensions, which pulled data from APIs. This meant that if the metrics weren’t native to Dynatrace, they wouldn’t be consumable into the Dynatrace platform. But,
- What if you want to keep track of a certain file’s size on a disk?
- What if you have an important InfluxDB you want to monitor?
- What if you want to know the number of currently running Ansible deployments, or the failed ones?
This blog will cover:
- A high-level overview of the “New Metrics Ingestion Methods”
- A “Cheat Sheet” for selecting which method is best for you
- A “Brief Review on Ingestion Methods”
- Shortcomings of this Early Adopter release, and what we hope to see in the future
- An example – “Ansible Tower Overview Dashboard”
New Metrics Ingestion Methods
Historically, teams could write OneAgent plugins, but they required development effort and a knowledge of Python. Now that Dynatrace has released the new Metric ingestion, any custom metrics can be sent to the AI-powered Dynatrace platform easier than ever. There are four main ways to achieve this, and they are:
- Metrics API v2 (OneAgent REST API)
- Dynatrace StatsD Implementation
- Dynatrace Telegraf Output (Dynatrace hasn’t written about this yet – official documentation provided)
- Scripting Languages (Shell)
Dynatrace has already written technical blogs about how to send the metrics (linked above), so this blog will aim to discuss the pros and cons of each method, along with giving a cheat sheet on which path is likely best depending on your business use case.
Cheat Sheet
When deciding which route to take, follow this cheat sheet:
- Is Telegraf already installed and gathering metrics? Use the Dynatrace Telegraf Plugin
- Or, does Telegraf has an Input Plugin built in for the technology that requires monitoring? Telegraf may still be the best route because capturing the metrics will be effortless.
- Is something already scraping metrics in StatsD format? Use the StatsD Implementation
- If none of the above, the best route is likely to use the Metrics API v2 / OneAgent REST API.
Brief Review on Ingestion Methods
Since Dynatrace has already written about each method, except Telegraf, those details won’t be duplicated in this blog. Instead, here’s a quick overview on each Ingestion Method:
- Dynatrace StatsD Implementation – If there’s an app that’s already emitting StatsD-formatted metrics, this implementation would be the most direct. The OneAgents listen on port 18125 for StatsD metrics sent via UDP. Dynatrace has enhanced the StatsD protocol to support dimensions (for tagging, filtering). The StatsD format is not as sleek as the new Dynatrace Metrics Syntax, so this path is not recommended unless StatsD is already present.
- Metrics API v2 (OneAgent REST API) – There is an API endpoint listening for metrics in the Dynatrace Metrics Syntax (if you happen to be familiar with Influx’s Influx Line Protocol, it’s almost identical)
- If the metrics are gathered from a host which has a OneAgent, they can be posted directly to localhost on port 14499 via HTTPS
- If the metrics are gathered from a host without a OneAgent, they can be posted to the Dynatrace Tenant’s “Metrics API v2”
- Dynatrace Telegraf Output – The latest releases of Telegraf now include a dedicated Dynatrace output, which makes sending metrics to Dynatrace extremely easy when Telegraf is installed. Telegraf can either push metrics to the local OneAgent or out to the Dynatrace cluster.
- If Telegraf is not yet installed, it still may be the easiest route forward if Telegraf natively supports a technology that needs to be monitored. The list of Telegraf “inputs” can be found here. Installing Telegraf is quite easy, and the Telegraf configuration is detailed well in the Dynatrace documentation.
- Scripting Languages (Shell) – If code has to be written to support outputting Dynatrace Metrics Syntax or StatsD metrics, the code can be slightly simplified by using the OneAgent dynatrace_ingest script provided with each OneAgent. This script can be invoked instead of writing networking code to push the metrics. Instead, metrics can simply be piped into this executable.
These ingestion methods allow Dynatrace to contend with open monitoring platforms, but they’re not without their own faults. Before moving to the example use case and dashboard, the most important caveats we discovered in Metric Ingestion will be discussed.
Early Adopter Shortcomings
Throughout evaluating this new functionality, a couple of missing features surfaced. Highlighted below are the most challenging issues faced, and then also a proposed solution to remedy the shortcoming.
No Query Language Functions
Problem – The largest shortcoming of this Explorer is the limited aggregation options presented.
Example Use Case –
- If an ingested metric is a COUNT over time, its value can become astronomically large. For a COUNT type of metric, a user may want to see the overall count, but likely the delta is more important.
- Another example is if there’s a metric which needs arithmetic applied to it – say the value of a query needs to be multiplied by 10 or divided by 100 – it’s not possible.
- And another example is when the difference between two different queries needs to be calculated (CPU Used – CPU System = CPU not used by OS) – it’s also not possible.
The workaround here is to modify the metrics before they’re sent to Dynatrace, but that’s not practical for a lot of use cases.
Proposed Solution – Add mathematical operators and query functions. For example, Grafana has dozens built into its product that make data manipulation at query time very easy.
Incomplete Metrics List in Explorer
Problem – The list of metrics presented in the Custom Charts Explorer is not complete, which can be misleading.
Example use case – If a user searches for “awx” they will find up to 100 metrics with a matching name. If that user scrolls through the list, exploring the new metrics, they may believe the 100 metrics were the only ones available, leading to confusion.
Proposed Solution – The list of metrics should indicate whether the list is complete.
New Metrics Registration is Slow
Problem – The time it takes for a new metric to be registered and queryable in Dynatrace takes up to 5 minutes.
Example use case – If you are very familiar with this new Metrics Ingestion, you can send metrics and assume they will properly register. But, when new users are testing out the functionality and developing their workflows, this delay can become a real headache.
Proposed Solution – As soon as a metric has been sent, it should be registered and then shown in the Metrics Explorer. Even if the data itself hasn’t been stored, the metric name should still be queryable near instantaneously.
Although these gaps in functionality are annoying at this time, the new Metrics Ingestion still allows for insightful 3rd-party dashboards to be made.
Example – Ansible Tower Overview Dashboard
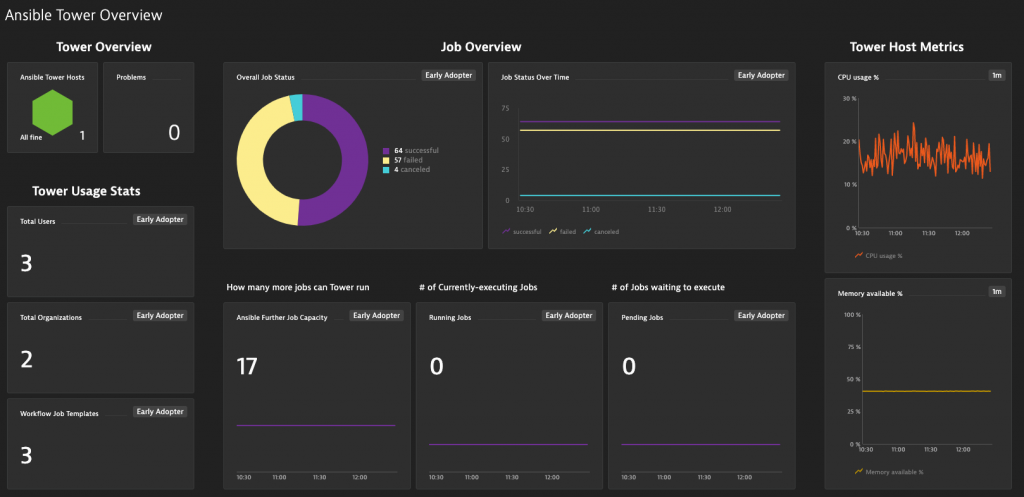
At Evolving Solutions, we’re a Red Hat Apex partner and we use a lot of Ansible. If you haven’t seen it yet, Ansible Tower is a very extensible solution for managing your deployment and configuration pipelines. I wanted to try to gather metrics from Ansible Tower’s Metrics API so I could track how many jobs were running and completed.
I wrote two applications which read from the local Ansible Tower Metrics API and scrapes those metrics. One of the apps prints the output to stdout, while the other pushes metrics via UDP to the StatsD Metrics listening port. The one which writes to stdout can be used as a Telegraf input (exec input) or piped into the dynatrace_ingest script.
With the data sent to Dynatrace, I made an example dashboard of how these metrics could be used. In the dashboard, I leveraged
- Dynatrace (Agent-gathered) Metrics:
- Host Health Overview
- Host Metrics
- Automatically Detected Problems
- Ansible Tower Metrics (through the Telegraf metrics ingest):
- Overall Job Status & Status Over Time (Successful vs Failed vs Cancelled jobs)
- Tower Job Capacity, number of Executing Jobs, and the number of Pending Jobs
- Ansible Tower Usage Stats (User count, Organizations count, Workflow count)

As you can see, sending these extra Ansible Tower Metrics to Dynatrace allows us to build a detailed overview of the Ansible Tower platform. With new features like open Metrics Ingestion, Dynatrace is continuing to differentiate itself and disrupt the APM market.
Ansible Tower monitoring is a great use case, but it’s only one of an endless number of use cases – do you have any systems you’d like deeper monitoring into with Dynatrace? Reach out to us at Evolving Solutions and we can help you gain complete visibility of your critical systems.
(21/01/11) – A previous version of this blog said that metrics could not have dimensions added or removed after they’ve been set. After speaking with Dynatrace Product Management, it was discovered that this is not true, and instead an obscure edge case was encountered. If you encounter hiccups with the new Metrics Ingestion, click the “Contact Us” button below.