IBM z16 – An Evolving Solutions Perspective Part 1: Pillar One

IBM April 5 2022 Announcement – An Evolving Solutions Perspective
Understanding IBM’s Announcement Pillars
Did you know that 72% of customer-facing workloads are backed by IBM Z applications and data? Or that 70% of business transactions run on IBM Z – including 90% of all credit card transactions.
In addition, IBM’s Z System Servers are deployed across the various industries, contributing to well over 30 billion transactions per day. IBM Z is the backbone of critical business processes and the world’s economy.
Given the importance of this platform, it comes as no surprise that IBM continues to enhance it.
IBM’s April 5, 2022 announcements are centered around four pillars. Those pillars are Decision Velocity, Quantum-safe Protection, Z and Cloud Experience, and Flexible Infrastructure.
Over the next few days, we’ll look at each pillar individually to better understand what they mean.
The new IBM Z keystone pillar is decision velocity
Decision Velocity focuses on the delivery of an on-chip AI accelerator that will allow Evolving Solutions’ mainframe clients to perform scoring on 100% of their transactions at the time that transaction enters their mainframe system.
Today, only a small percentage of these transactions are scored, and the scoring typically takes place off-platform. IBM’s z16 Server fundamentally changes your ability to score a transaction, significantly improving your organization’s fraudulent transaction risk posture. This will translate into significant dollar savings each year.
No matter the industry, the cost of fraud will continue to grow and impact your business.
For example, in the the Healthcare industry, it is common to process millions of claims per week. These claims run through COBOL and a subset of those claims are subjected to off-platform adjudication in search of fraud.
With the advent of IBM’s z16 Server, it is now possible to train Neural Networks on GPU’s off-platform and then package the trained models in a format that is portable to System Z. Doing so, would allow pick a client, pick an industry to inspect for fraud against 100% of their pick a workload.
The TELUM Chip
The IBM z16 server offers an industry-first AI accelerator that is designed for low latency, high thru-put workloads allowing IBM clients to leverage AI in real-time. With this new design, you can bring state of the art deep learning inference even for your most latency sensitive workloads, which provides the ability to examine every transaction.
The Ecosystem
All the above sounds impressive, but it is not worth that much if tooling is not available to make use of it transparently. That brings us to looking at how IBM exposed the on-chip inference engine transparently to commonly used AI frameworks.
What you see in the chart below is the work IBM has performed as part of the lower-level software ecosystem. The changes IBM made will allow AI frameworks that you use today to transparently invoke these lower-level APIs.
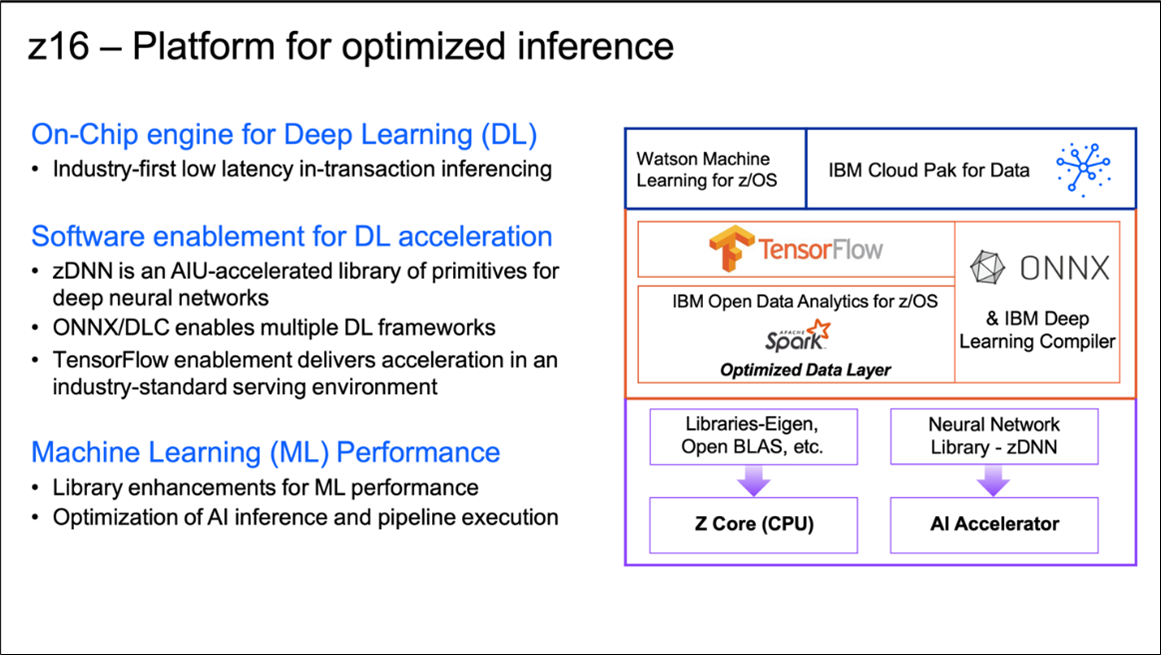
If you look at the lower right side of the stack you will see the AI Accelerator on the z16 chip. What IBM has built on top of this chip is a library called zDNN – Z Deep Neural Network. This library is packaged as part of the operating system, both z/OS and Linux on z distributions. If you are familiar with Intel and it’s use of GPUs in this space, the zDNN library contains a set of primitives that support Deep Neural Networks. These primitives have been instrumented by IBM to take advantage of the underlying hardware acceleration.
IBM does not expect application developers to call this library directly. What will call this library is IBM’s Deep Learning Compiler (IBM DLC). IBM’s DLC will take models that are in ONNX standard format, compile them and create a z16-optimized inference program by calling the zDNN library.
The zDNN library will be leveraged by the DLC as well as the TensorFlow Framework given the work IBM has performed to this open source framework. The zDNN library could be used by AI framework developers, but not application programmers or data scientists.
If you look at the lower left side of the stack you see the z16 core (CPU). In addition to the AI Acceleration library support, it now provides vectorization support and SIMD instructions that are commonly used in machine learning and deep learning. Single Instruction Multiple Data (SIMD) has been on this platform since 2015. What is new is that IBM has optimized a number of the popular open-source libraries as listed on the left side of this chart. For example, Open BLAS is a linear algebra library that has been optimized to leverage SIMD technology.
The back-end instrumentation that IBM has performed on this chart is what allows your models to be deployed to this platform with no changes.
How the magic happens
So what makes IBM so sure their z16 on-chip inference engine will offer the absolute lowest latency in the industry? This chart reveals how the magic happens.
Starting from the top, we see a TensorFlow model that is making a matrix-multiply request. Through a device plug-in (IBM provided) to the TensorFlow container, we see a call to the z/OS or Linux zDNN library.
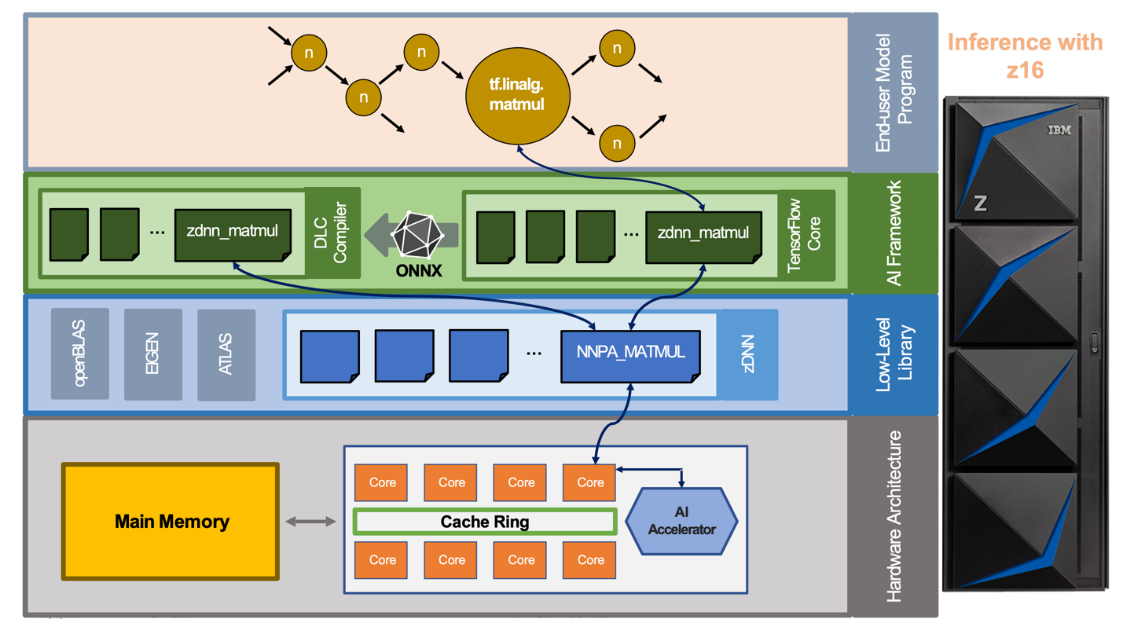
The zDNN Library is made to support this matrix mMultiplication request. The zDNN library will issue a Neural Network Processing Assist (NNPA) machine instruction. This instruction is new to the z16 server (the magic).
The NNPA Matrix Multiplication machine instruction is executed on the z16 core which calls the AI Accelerator synchronously. Note the immediate access to the data associated with the MATMUL instruction. For those familiar with this platform, also note that all this processing is running on a zIIP – no software costs.
This chart also shows the path-length that will be taken when an ONNX model is processed using IBM’s Deep Learning Compiler. Again, the zDLC will invoke the zDNN library resulting in the NNPA machine instruction call. Following that call, the flow remains the same.
As a reminder, ONNX is an open format used to represent both deep learning and traditional models. ONNX is designed to express machine learning models while offering interoperability across different frameworks. IBM recognized this capability and developed the Deep Learning Compiler to allow ONNX models to run unchanged on the z16 server.
I look forward to sharing more in the next installment of this blog series.
If you are interested in learning more about the IBM Z16 server, or components of IBM’s broader April 5th announcement, feel free to reach out to Jim Fyffe via LinkedIn or send an email toJim.F@evolvingsol.com.